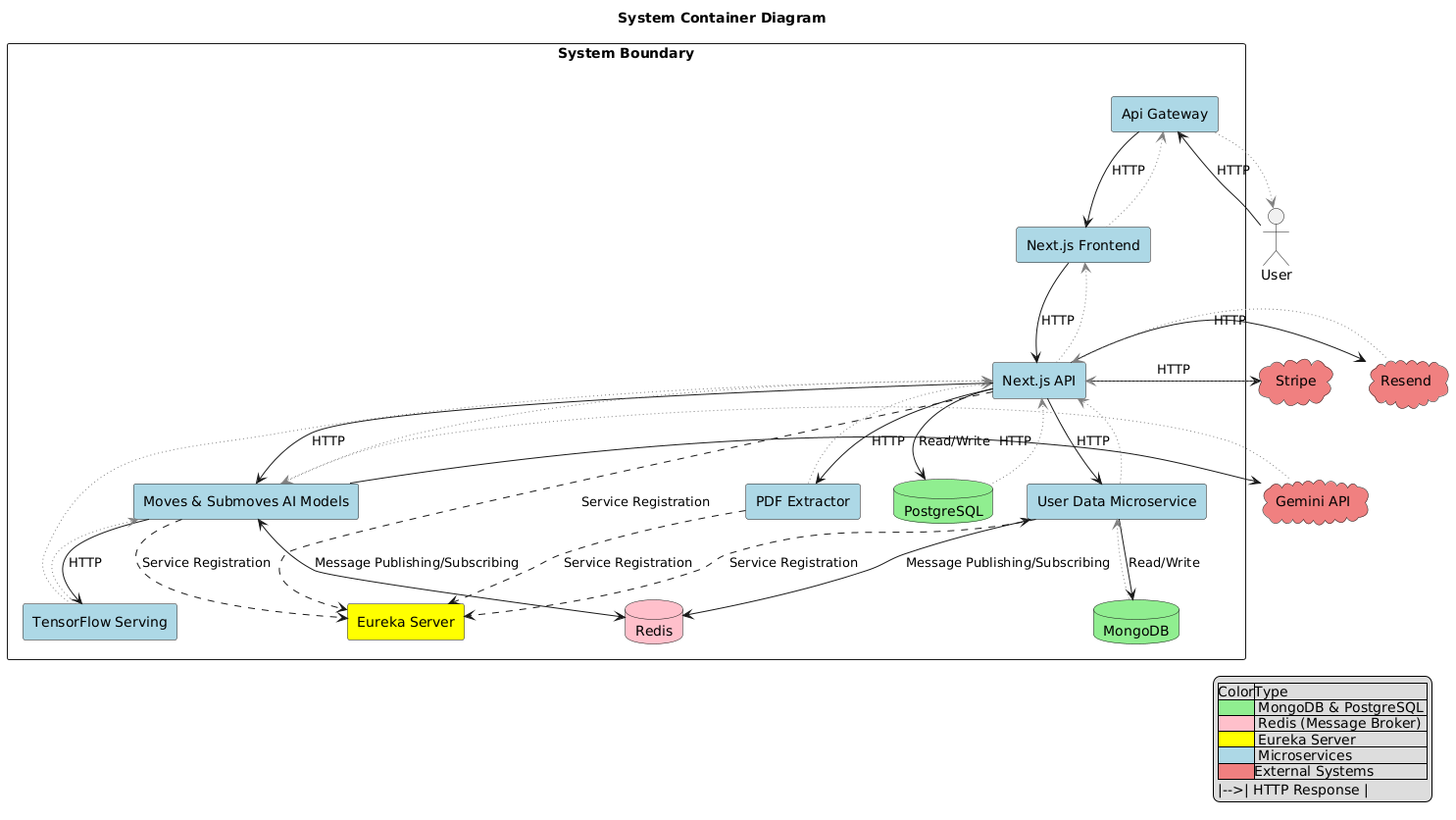
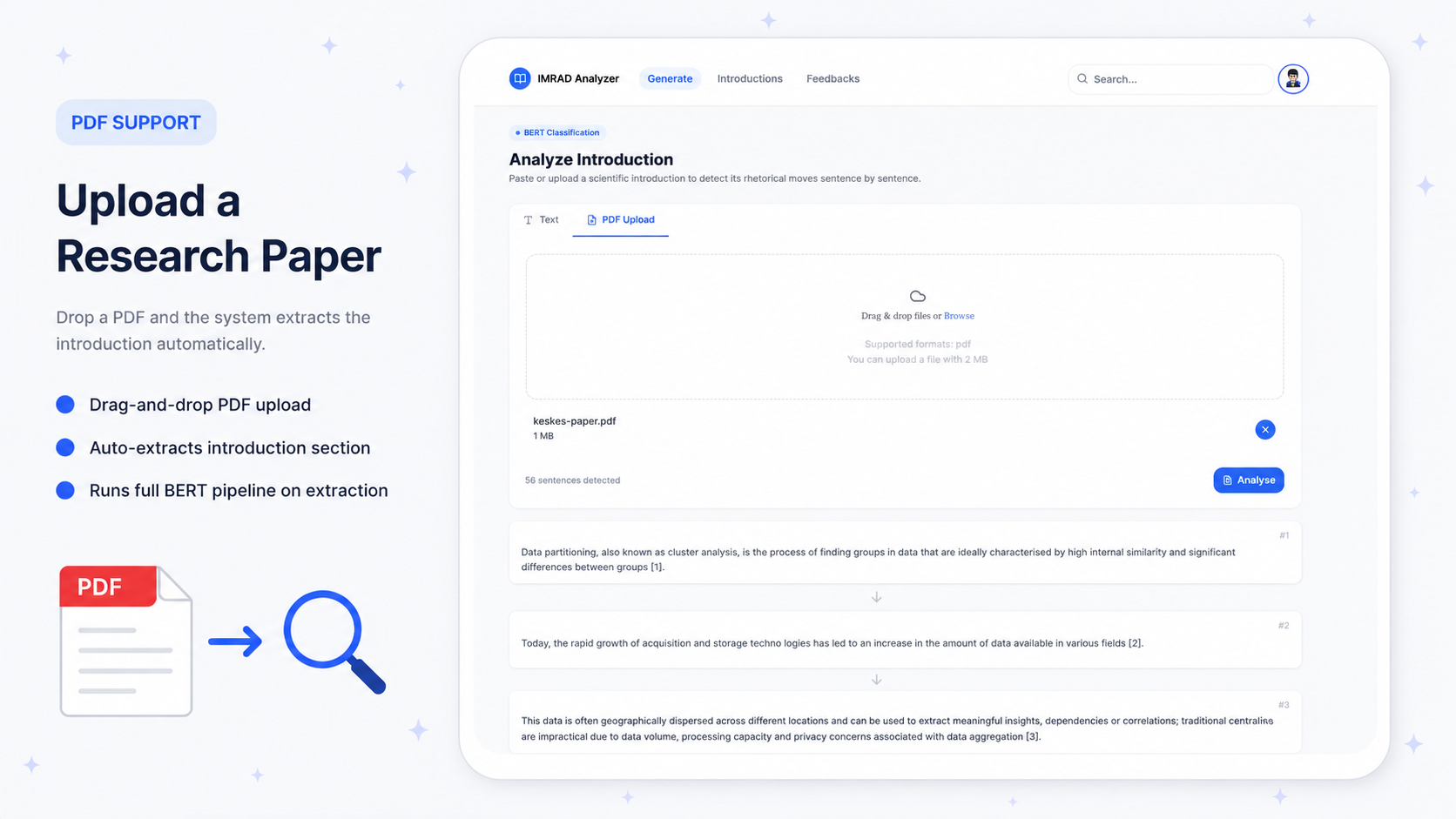
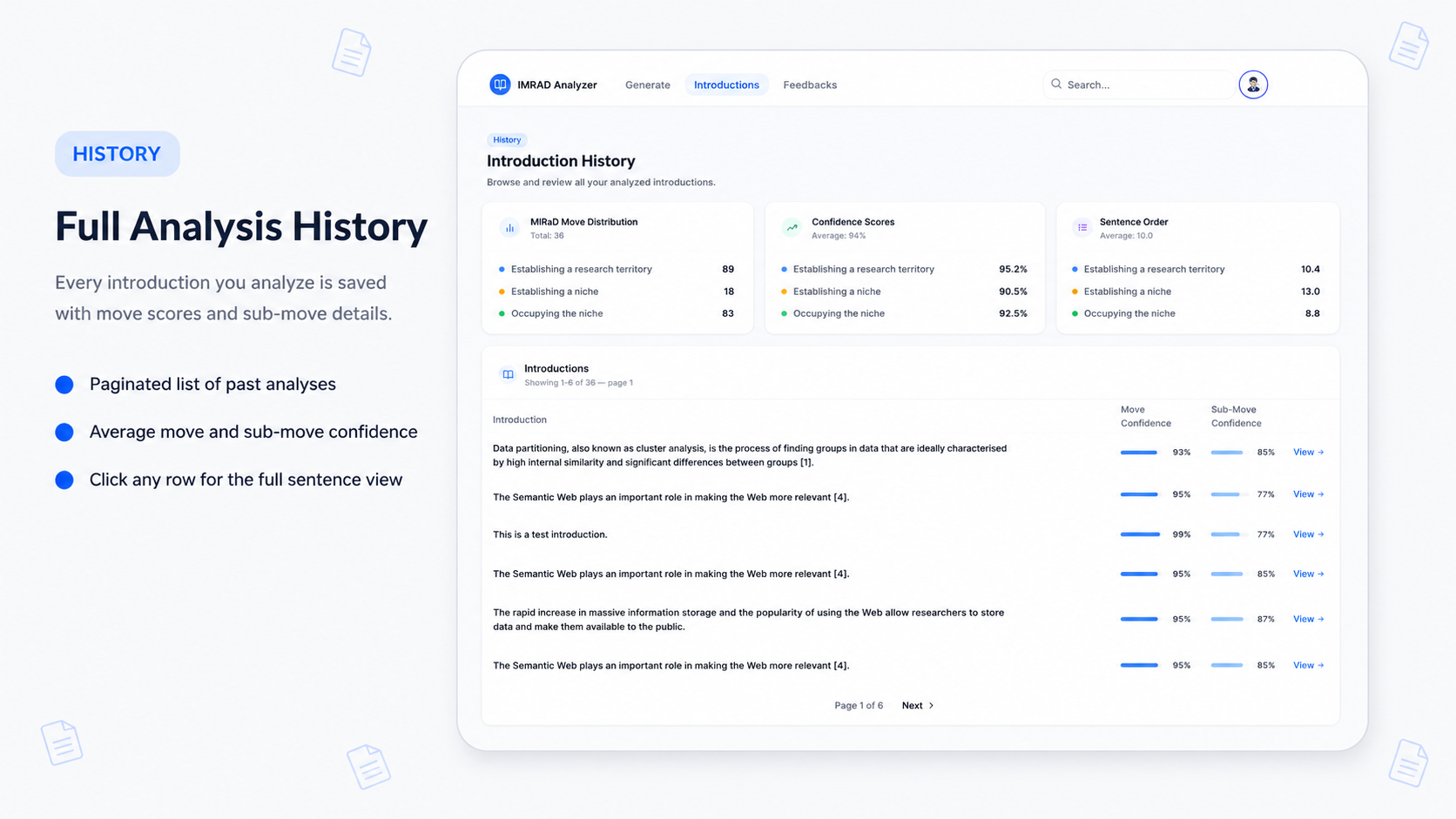
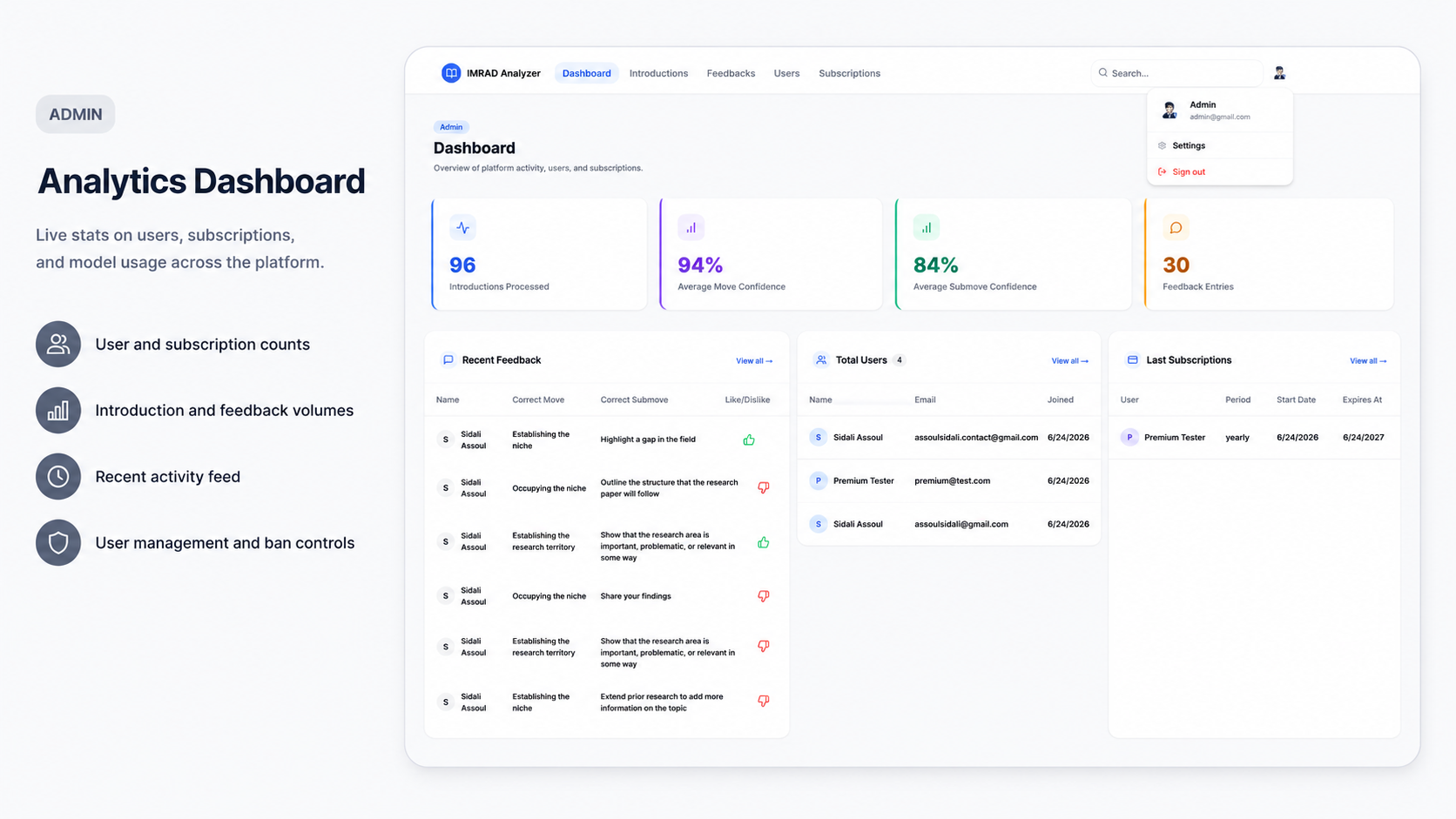
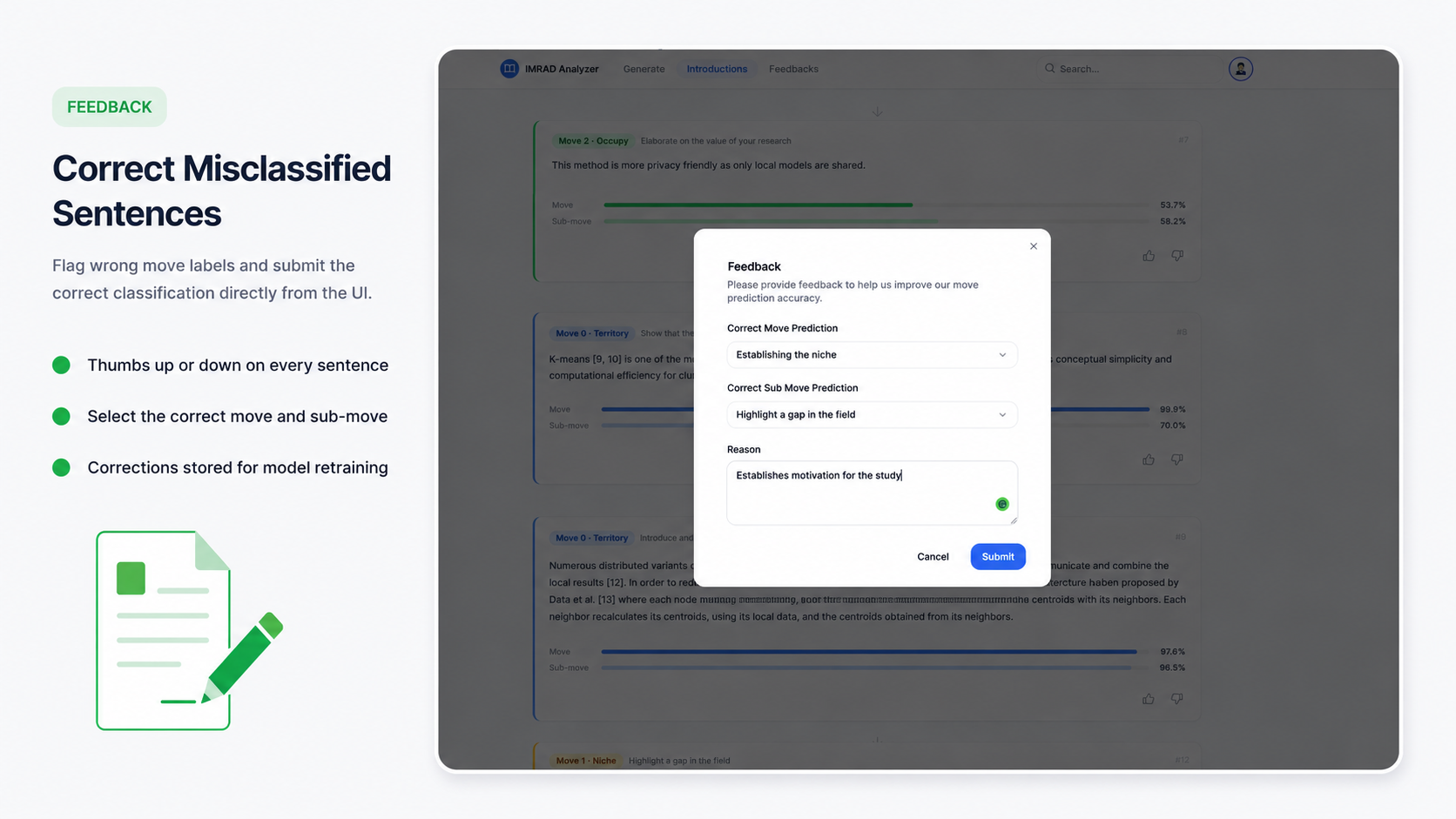
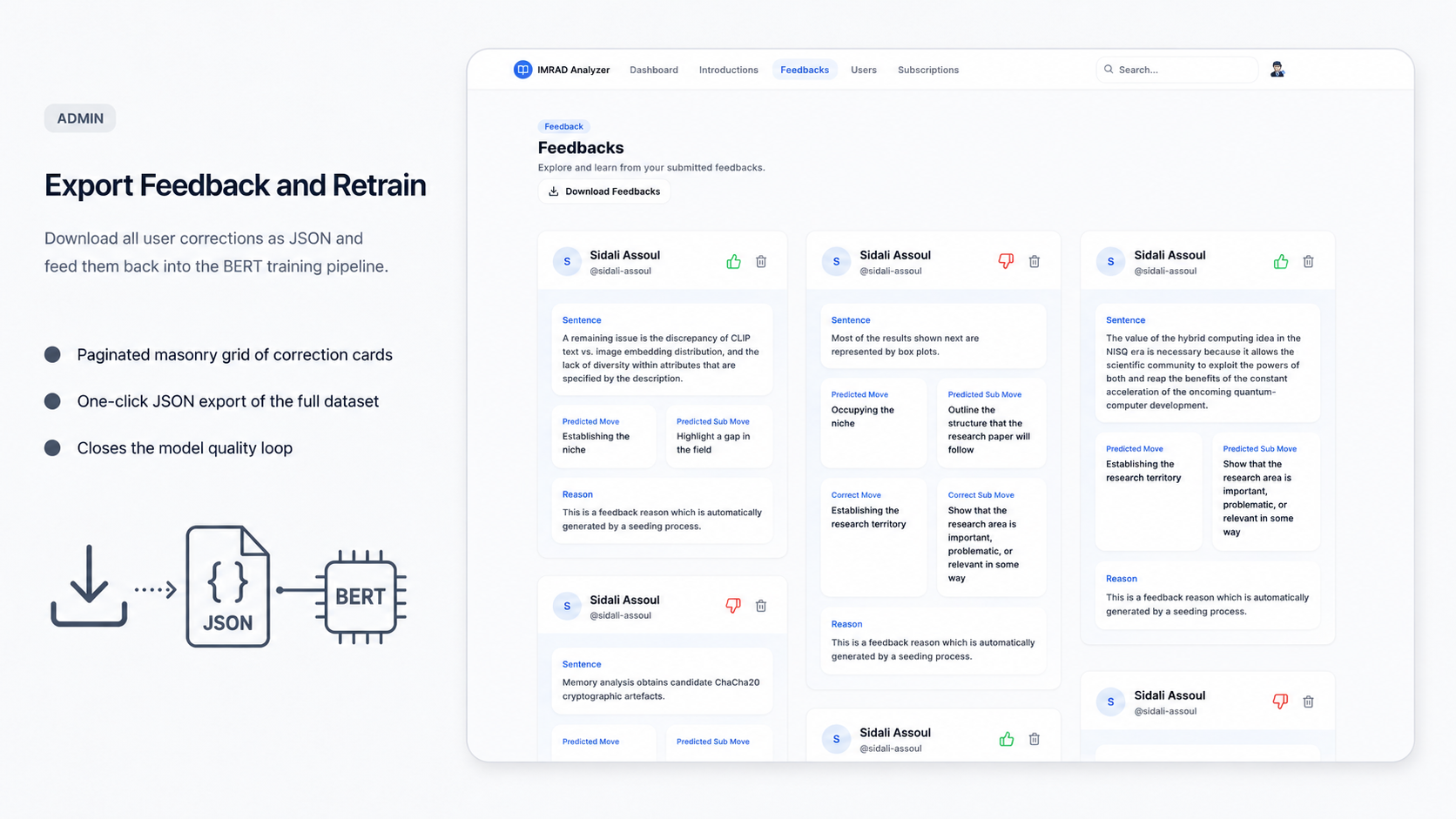
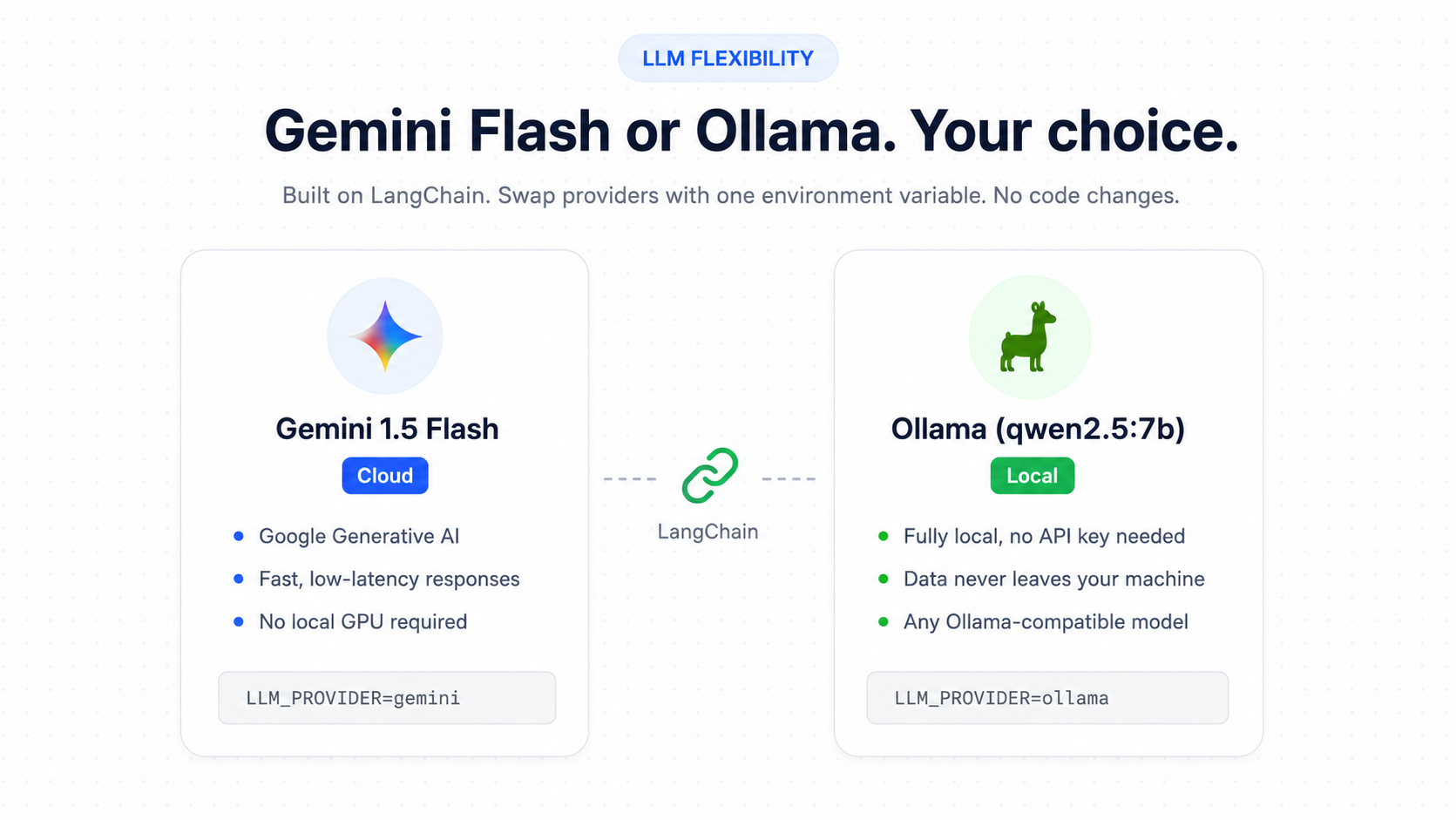
01
8-node Microservice Architecture.
- Nginx (gateway)
- Spring Cloud Eureka (discovery)
- Next.js (frontend and API)
- PDF extractor (FastAPI)
- Tensorflow Serving
- Moves and Sub-moves AI microservices (FastAPI with langchain)
- User data microservice (MongoDB, Express.js)
- Redis as a message broker.