Reflections on My Engineering and Master's Thesis: Building an AI-Powered IMRaD Analysis SaaS Platform
Last updated on
How did everything start?
It’s March 2024, and I’ve totally lost track of time, as I’ve been fully immersed in a long-term freelancing mission with an interesting Upwork client.
Then, I was soon to find out that I was running out of time! I needed to start working on my graduation project.
But wait, I haven’t even chosen a theme. No, but worse, I haven’t even chosen a suitable supervisor for it.
So just after finishing my part-time freelancing hours, I started leafing through the themes list, looking for an interesting one that could capture my curiosity and satisfy my knowledge hunger (I was craving NLP, btw).
After a few hours of research and contemplation, I stumbled upon an interesting project theme entitled “Writing support system: IMRD text analysis.”
I thought to myself, “A ‘writing support system’ implies that the project might involve some software design, which is something I’ve always loved, and ‘text analysis’ means finally having a chance to fulfill my craving for NLP with a project that actually looks interesting.”
The project was at a laboratory in the university where I’ve been studying, ESI-SBA, known as the “Higher School of Computer Science Sidi Bel Abbès.” I have a lot of nice memories about the supervisor as well, as he taught me two modules in the past: File Systems and Data Structures in my second year and Data Analysis in my fourth year. So, going with that supervisor was just a no-brainer for me.
I looked up his teaching schedule and found out he was teaching the 4th-year students at 9:00 AM, so I asked a friend to let him know I was genuinely interested in the theme he suggested and that I wanted to meet him to discuss my application for the project.
As soon as he got out of class, I thanked my friend and approached the supervisor to discuss the details. My request was met with warm approval; he explained the problem briefly and sent me some PDFs to dive deeper into it.
I immediately went to the university reading room and started skimming through the documents the supervisor sent, full of eagerness and joy, completely losing myself in a flow state. Finally, “I’m going to work on a serious NLP research project!”
Table of Contents
- Not one graduation project, but actually two!
- But what does IMRAD actually mean?
- Master’s Thesis
- Engineering Thesis
- Dataset Preparation
- Phase 1: Baseline Model (V1)
- Phase 2: Model Refinement (V2)
- Phase 3: Model Enhancement and Dataset Augmentation (V3)
- A Microservices-Based SaaS Platform
- Data Models
- Conclusion
Not one graduation project, but actually two!
In Algeria, we don’t just pick one; we’re required to complete both a master’s thesis and an engineering project at the same time.
Both my master’s and engineering theses are about IMRAD classification, but each one focuses on a different angle of it.
But what does IMRAD actually mean?
Before we dive any further, there’s something important that you need to be aware of.
Research papers are the medium that is used to communicate scientific findings between researchers.
Subjectivity has no place in science, so we can’t mix scientific findings with other kinds of literature. And that’s where IMRad is useful.
IMRad stands for introduction, methods, results, and discussion. It’s a logical and objective framework for writing scientific papers.
In the Introduction section, the author should present what’s known about the research area and all the existing work that’s been done on it, show the motivation behind his own study, and then conclude by showing how his research brings a unique perspective to the field.
In the methods section, the researcher simply tries to make his research reproducible by describing the exact steps and materials he used to create his experiment.
You can think of it as a step-by-step guide to recreate the experiment under the same conditions.
Naturally when talking about something, we tend to both describe it and explain it in detail, all in parallel.
I guess that all developers were victim of this at some stage of their carriers, we like explaining the technical details of our project before even finishing describing the business side of it.
Well, mixing the two together makes it difficult for the listener or the paper audience to understand both the results and your interpretation.
We definitely need to pause a little bit between the two sections and separate the two concerns, “describing” and “explaining,” to give the audience enough time to process and comprehend everything incrementally.
In the IMRaD framework, the author is required to first describe the results and data in an objective way with normal text, tables, figures, equations, code, and so on.
And then and only then does it interpret and explain the results in the discussion section.
Master’s Thesis
Think about this: there are millions of researchers around the world, which means that scientific papers are published daily at crazy rates.
Ok, now imagine that you’re a researcher sifting through all that vast sea of knowledge; it won’t be an effortless task, right?
To solve this problem, we need something that tells us which section of the text is a discussion and which one is a result.
We need a classifier that is trained on text data that is annotated with the four types of IMRaD sections.
This latter can be used internally by search engines to index the papers and provide features such as searching, filtering, and querying literature based on a specific IMRaD section.
Well, that’s what I studied and even implemented in my master’s thesis entitled “Leveraging BERT and Data Augmentation for Robust Classification of IMRAD Sections in Research Papers.”
After sifting through that vast sea of knowledge myself, reading a ton of research papers, I stumbled upon an interesting one that included a link to a publicly available dataset.
And to my surprise, it included a bunch of paragraphs extracted from various research papers with their corresponding IMRaD annotation and an extra Related Work label.
So I got the following hypothesis or research question:
Can a BERT model, enhanced with a custom pipeline of data processing, LLM-based outlier detection, and data augmentation, achieve a high accuracy in the classification of IMRaD sections of scientific papers and outperform traditional machine learning approaches?
State of the Art
In a master’s thesis you need to look into the current research before you can get started with your own approach and see what the state of the art is.
Therefore, I spent a lot of time looking for relevant papers, reading, filtering, and carefully choosing four key studies that I read and compared based on data size, annotation method, models used, and accuracy.
I also studied a variety of relevant topics, including classic NLP techniques; traditional machine learning classifiers such as TF-IDF, BoW, Word2Vec, Naive Bayes, and SVM; and modern deep learning advancements such as pre-trained models (BERT and GPT), LLMs, and prompt engineering.
Experimentation Pipeline And Contributions
The experimentation section is normally optional in a master’s thesis, but I decided to add it anyway.
Here’s a clear summary of the end-to-end experimental pipeline I built:
- Data collection from Hugging Face (~530k rows), then exploration, cleaning (removing non-natural language elements), and balancing to ~25k rows
- Traditional baseline (Logistic Regression + TF-IDF) accuracy: 63.78%
- Initial BERT fine-tuning at F1-score 0.7309
- LLM-based outlier detection/cleaning + data augmentation (generating synthetic paragraphs based on similarity with the existing ones to reach ~100k rows)
- Final fine-tuned BERT model with an F1-score of 0.9172 showing massive progressive gains over baseline
The execution of the pipeline resulted in the creation of a newly annotated dataset (approx. 100k rows) and the training of a highly accurate (99.2% F1 scores) fine-tuned BERT classifier, both published on Hugging Face.
Engineering Thesis
For my graduation thesis, “Leveraging Gemini Pro and BERT for Automated IMRaD Classification: A Novel Dataset and SaaS Platform,” I developed a project that covers two main domains: NLP deep learning research and systems engineering.
I know. Yeah. It would have been much easier to just keep on with the same topic as my master’s thesis and do one study, research, and engineering study.
But I’m not the kind to give up on something.
My supervisor gave me the task of analyzing introductions, and no matter the difficulties I had due to the absence of a proper dataset, I wasn’t going to let the topic slide just like that.
Before I get into the nitty gritty of the research and development phases later in this post, here is a quick summary of my main contributions to the research and engineering parts of the project:
Research Contributions
- Created a Gemini Pro data pipeline that included baseline generation, prompt refinement, outlier detection, and data augmentation.
- Used Random Forest, Logistic Regression, SVM, KNN, and Naive Bayes classifiers to validate the outputs incrementally.
- Created a custom 169,000 sentence dataset and fine-tuned four hierarchical BERT models to boost accuracy from a baseline of 44.61% to a surprisingly high peak F1 score of 98.21%.
Engineering Contributions
Basically, in the engineering part, I took the outputs of the research part, which are the four hierarchical BERT classifiers, and then built a whole microservices-based SaaS platform on top of them.
The SaaS platform is broken down over the network into 8 nodes:
| Nodes | Technologies |
|---|---|
| Gateway | Nginx |
| Service Discovery | Spring Cloud Eureka |
| Frontend + API | Next.js, Postgres, Stripe API |
| PDF Extraction | FastAPI |
| BERT Models | TensorFlow Serving Container |
| AI Moves & Sub Moves | FastAPI, LangChain, Gemini Pro |
| User Data Service | Express.js, MongoDB |
| Message Broker | Redis |
I’d also like to add that I’ve followed the SDLC, or software development life cycle, and written full documentation, starting from requirements analysis and specification to system design, implementation, and testing, to the delivery of the platform.
Dataset Preparation
Before I could begin the research and development of my engineering project, I encountered a hurdle that almost made me give up on the theme.
I was in doubt and perplexity when I found that there are no research papers or public datasets that provide sentence-level labels for IMRaD introduction moves and sub-moves.
My master’s thesis went a bit smoother because I found a lot of research papers and publicly annotated datasets that provide “I,” “M,” “R,” and “D” labels for paragraphs extracted from different papers. One of them is the “unarXive” dataset.
[ Unarxive Dataset ]
(Labels: I,M,R,D,W)
|
| Filter &
| Cleaning
v
[ Filtered Results ]
+-----------------------+---------+
| Text (Excerpt) | Label |
+-----------------------+---------+
| "Food recom..." | I |
| "Previous stu..." | R |
| "As discussed..." | D |
| "Initially..." | I |
| "The method..." | M |
| "Furthermore..." | R |
| "Results show..." | D |
+-----------------------+---------+
CHALLENGES:
* Section-level annotations only.
* Lack of sentence-level
granularity.Since I couldn’t make use of the “Unarxive” dataset directly, the only solution for my problem was either paying for human annotators or using the closest form of intelligence that science could achieve, “LLMs,” or large language models.
Fortunately, that option was cheap at the time because the free tier for Gemini Pro was so generous, and I also used all the $150 free credit on my Google Cloud account.
As I could neither obtain public data nor afford a human annotator, I designed a three-phase approach (V1→V2→V3) to overcome the lack of a sentence-level granular dataset and to create a custom one tailored to my specific needs.
Phase 1: Baseline Model (V1)
My solution to this problem was incremental.
I started with a baseline model using the following workflow:
- I’ve chosen random introductions from the cleaned and filtered “unarXive” dataset.
- I broke the introductions into sentences.
- I fed every individual sentence into a Gemini LLM instance while guiding it with a well-crafted classification prompt.
- I then used the generated data to finetune a BERT model for classification.
- This model achieved an accuracy of 44.61%, which has, in my opinion, shown potential (because the accuracy was a little higher than a random guess for three classes).
[ unarxive dataset ]
↳ Cleaned & filtered
|
v
[ Introductions ]
|
(split)
v
[ Sentences ]
|
v
[ Gemini LLMs ] <--- [ Classification Prompt ]
|
(outputs)
v
[ Predictions ]
↳ Sentence -> Move 3
↳ Sentence -> Move 1
↳ Sentence -> Move 2LLMs by design are generalists. They are intended to handle any sort of situation. So how do we get them to do a particular task like classification?
That’s where prompt engineering comes in. A prompt is essentially a set of instructions written in raw natural text.
This allows us to limit the LLM’s behavior, or specialize it for a given task, like classification, summarization, etc.
In this version, I used a relatively simple prompt to tell each Gemini Pro instance to classify a given sentence into its corresponding IMRaD move.
Phase 2: Model Refinement (V2)
In the second version of the pipeline, I decided to focus on enhancing the prompt.
I thought to myself, ‘What if the reason behind that low accuracy is that Gemini Pro didn’t have enough context about the introduction? Maybe I should embed the whole introduction in the prompt.’
In addition to that, instead of classifying only the moves, the enhanced prompt would allow Gemini to classify both moves and submoves in one go.
The comparative table below explains the steps that were taken.
| Feature | Initial Prompts | Enhanced Prompts |
| Input | A single sentence. | A single introduction. |
| Classification Scope | Classifies only moves. | Classifies both moves and submoves in one go. |
| Output | A single-sentence prediction. | A list of sentence predictions (with move and submove labels). |
These last changes were made to increase overall annotation speed and to give Gemini Pro a better understanding of every move by knowing the corresponding sub moves.
To test the quality of the new dataset, I used simple ML classifiers with TF-IDF vectorization to avoid time and resource consumption of using a heavy model like BERT for simple benchmarking. The results were a surprise!
| Classifier | Accuracy |
| Random Forest | 60.7 % |
| Logistic Regression | 60.0 % |
| Neural Network (Keras) | 57.5 % |
| Naive Bayes | 55.6 % |
| K-Nearest Neighbors | 54.0 % |
| Decision Tree | 51.6 % |
Every single one of them managed to outperform the previous BERT model. That was a clear sign that I was making progress; the prompt enhancement was fruitful.
Phase 3: Model Enhancement and Dataset Augmentation (V3)
For my final model, I built a custom dataset of 169k sentences using a custom pipeline which sat on top of the V2 generated data, with Gemini based outlier detection, Gemini data augmentation, and fine-tuning 4 custom BERT models.
The final generated data was used to fine-tune four hierarchical, specialized BERT models, all published on Hugging Face: Move Classifier, Move 0 Sub-move Classifier, Move 1 Sub-move Classifier, and Move 2 Sub-move Classifier.
Believe me when I tell you that I was bursting with joy when I saw the validation and training accuracy graphs increasing in parallel.
When the F1 score hit 0.98 for overall move classification and exceeded 0.89 for submove classification, I was literally screaming, “Yes, yes! It’s not overfitting, and the F1 score is above 98%!”
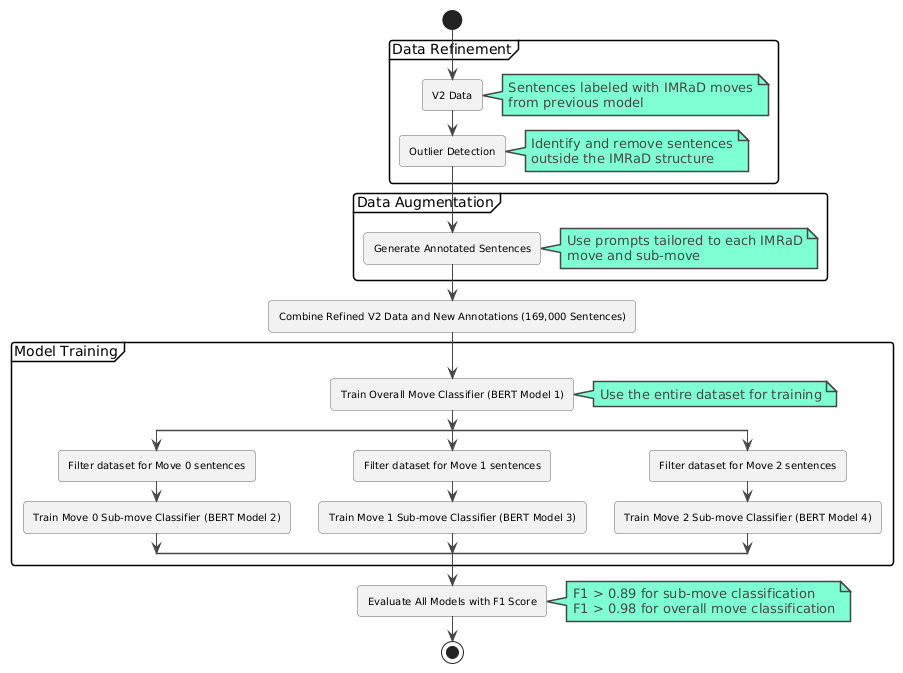
This previous pipeline was powered by a series of carefully designed prompts for Gemini Pro.
[ V2 Prompt ]
+
[ Moves & Sub-moves ]
examples
|
v
(extends)
|
+--> [ AI Outlier Detection ]
|
+--> [ AI Data Augmentation ]
The base prompt is the one I used in V2, with some extra ingredients, like enumerating all the moves and submoves and providing several examples for the model to follow for each submove.
The outlier detection and data augmentation prompts are based on this base prompt with a few additional modifications on top.
The outlier detection prompt makes Gemini Pro go back over previous predictions and mark them as outliers and filters them or corrects them if they are mistaken.
Then the data augmentation prompt asks Gemini to generate more sentences for each move, strictly respecting a bunch of rules.
A Microservices-Based SaaS Platform
After publishing the final four hierarchical classification BERT models, I decided to create a SaaS platform that makes full use of these models and helps researchers and students easily analyze the rhetorical structure of scientific paper introductions.
The IMRaD Analysis Platform offers the following key features:
- Upload a research paper (PDF) or manually paste introduction text
- Automatic sentence segmentation and classification of IMRaD moves and sub-moves with confidence scores
- Clean and intuitive visual interface for viewing analysis results
- User feedback system allowing corrections to predictions to help improve the model
- Premium features including detailed summaries and AI-generated author thought process
- Full user account management with Stripe subscription handling
- Administrator tools for managing users, reviewing feedback, and monitoring platform statistics
Microservices Breakdown
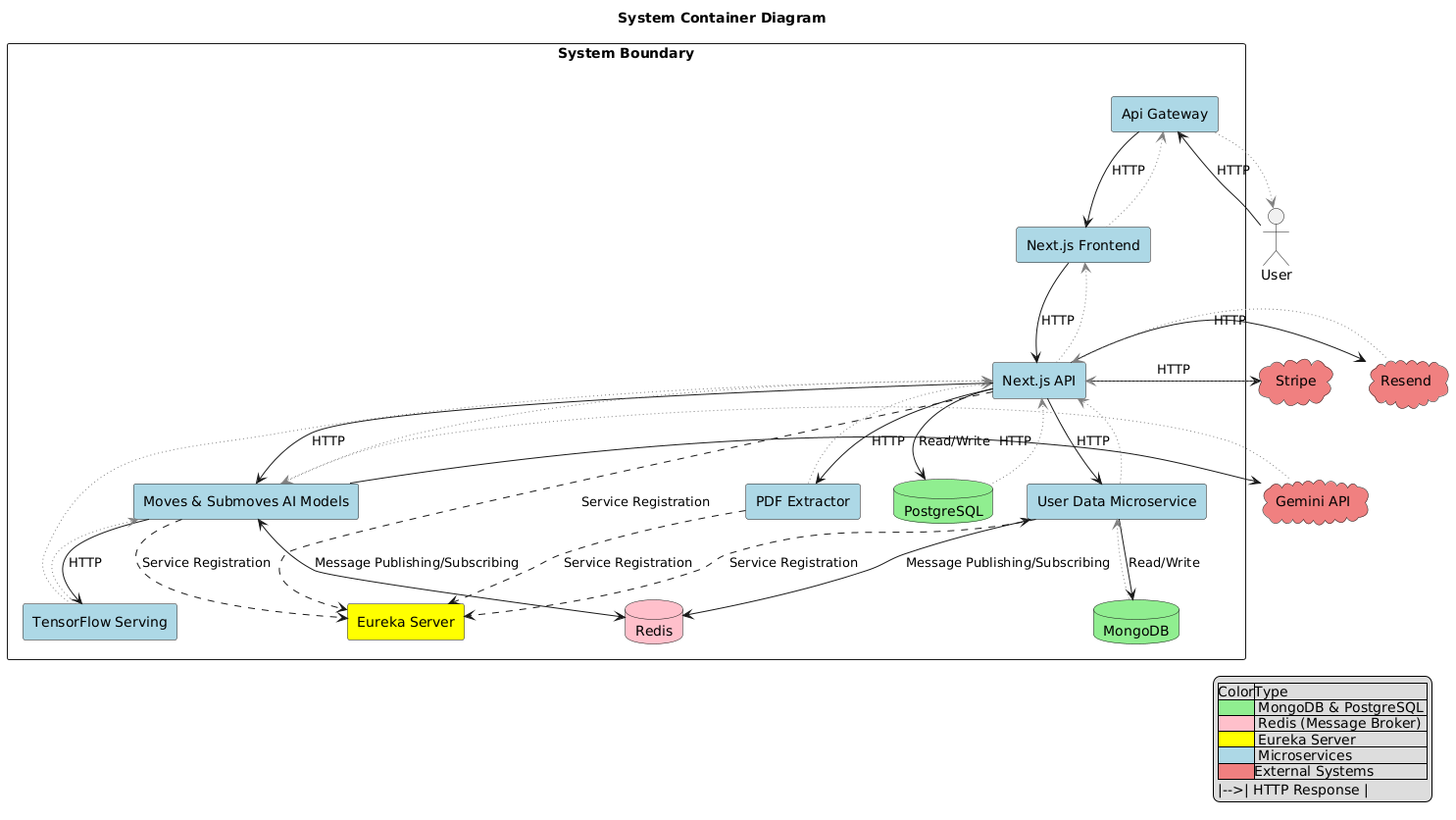
Let’s review the key microservices in our platform.
The whole system is accessed via the API Gateway.
This component takes care of forwarding and load balancing user requests to our active internal microservice instances.
All the microservices self-register automatically with the Eureka Discovery Server, which is a dynamic index of all live instances of each service.
Then we have the Next.js microservice, which is actually composed of two parts:
First, a frontend, which is responsible for rendering all the individual pages.
And a backend that does the following:
- Authentication and authorisation
- Managing subscriptions via the third-party service Stripe
- It serves as a composition service that calls and aggregates results from multiple internal microservices.
- It doesn’t hardcode the IP and port of each microservice, but registers with the discovery server, gets all the active instances of a given microservice, and then does client-side load balancing between the active instances of each called microservice.
- Send transactional emails with the Resend third-party API
- Use of PostgreSQL database for persistent data
Then we have the TensorFlow Serving microservice that serves our fine-tuned BERT models with optimized production-grade access.
The AI Moves and Sub-moves microservice does batch prediction for moves and sub-moves by forwarding the requests to TensorFlow Serving. It also connects with the Gemini API to generate the intro summary as well as the hypothetical thought process of the author behind switching between the different moves and sub-moves when writing the intro.
The PDF Extractor microservice built on FastAPI that extracts introductions for uploaded research papers is on the same repository.
The User Data microservice stores user predictions and handles feedback. It uses a NoSQL MongoDB database to persist data.
Finally, Redis is used as an in-memory database and message broker to enable asynchronous communication between the different microservices.
Data Models
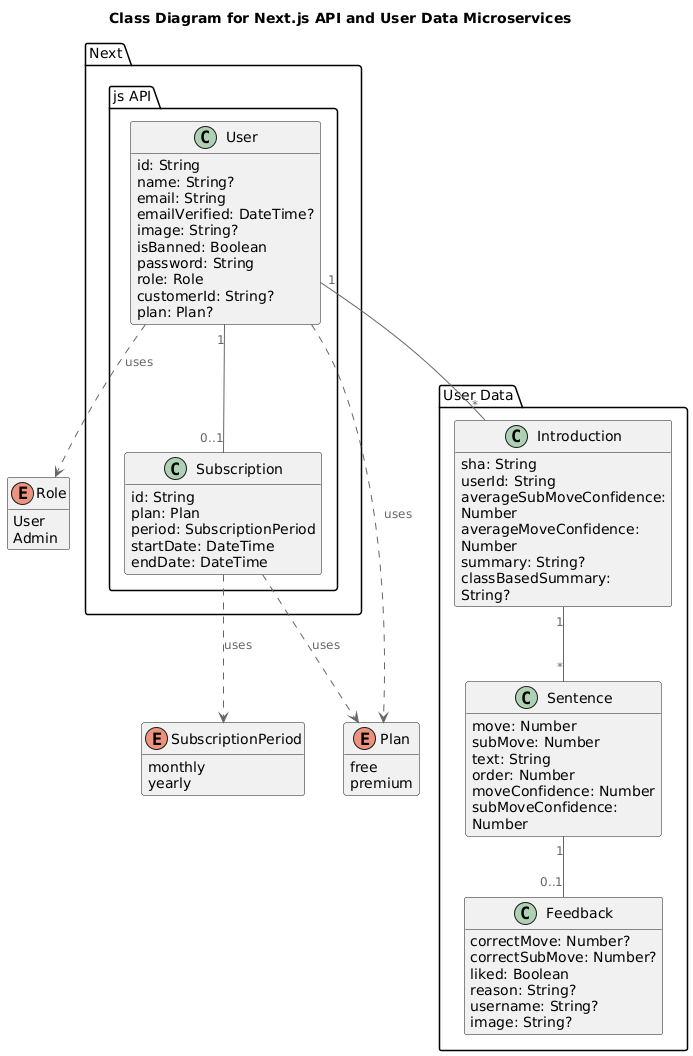
Here’s a quick look at the data model of our platform.
The Next.js microservice is responsible for two entities: User and Subscription. It uses a SQL database (PostgreSQL).
The User Data Microservice is responsible for managing three entities: introduction, sentence, and feedback.
As everything usually gets queried together, I decided to store everything as a MongoDB document.
Since an introduction can have many sentences, and we usually query them with introductions, we embedded them in a subarray within the introduction document.
The feedback, in its turn, also got embedded within the sentence and, therefore, by transitivity, within the introduction document.
The User and Introduction entities are in different microservices and have completely different databases, but they are related in a one-to-many relationship (a user can have many introductions) and linked via a foreign key, “introductionId.” The introduction document
Conclusion
If you’ve reached this point, I’d like to thank you for your attentive reading of these memories of almost two years ago.
Honestly, like any other student in my university, the thoughts of missing the graduation deadline, facing judges, and presenting my work in a really short time never left my mind. It was a really rewarding journey and exceptional experience that I want to repeat again. Hopefully when I work with other interesting NLP or advanced deep learning projects.
After months of studying NLP, reading research papers, and listening to podcasts about it during my walks, I went from having no dataset to building a 169k-sentence annotated dataset, fine-tuning four hierarchical BERT models to an F1 score of 98.21%, and constructing a complete microservices platform.
If you have any questions or thoughts about all of this, let me know; my DMs are always open. I list all my social links on my contact page.
Enjoyed this article?
I'm currently open to new roles — remote-first or international. If something resonated or you'd like to collaborate, I'd love to hear from you.

This article was originally published on https://sidaliassoul.com/blog/reflections-on-my-engineering-and-masters-thesis-building-an-ai-powered-imrad-analysis-saas-platform/. It was written by a human and polished using grammar tools for clarity.